Kubernetes 指南
前提
你需要在每台机器上安装以下的软件包:
1 2 3 kubeadm:用来初始化集群的指令。 kubelet:在集群中的每个节点上用来启动 Pod 和容器等。 kubectl:用来与集群通信的命令行工具。
允许 iptables 检查桥接流量
1 2 3 4 5 6 7 8 9 10 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system
关闭 selinux
1 2 3 4 5 # 临时关闭setenforce setenforce 0 # 永久关闭 vi /etc/selinux/config SELINUX=disabled
设置主机名
1 2 3 vi /etc/hosts 192.168.67.128 k8sm01 192.168.67.129 k8sm02
安装 k8s ==注意==:别安装最新版本的 kubelet kubeadm kubectl
kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers 这个命令可能拉取不到最新的k8s组件
(==推荐==)如果计划将单个控制平面 kubeadm 集群升级成高可用, 你应该指定 --control-plane-endpoint 为所有控制平面节点设置共享端点。 端点可以是负载均衡器的 DNS 名称或 IP 地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 # 添加k8s yum源 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg # 这个指定是在上面的镜像中排除下面的三个软件包 # exclude=kubelet kubeadm kubectl EOF # 查看版本,安装倒数第二个版本 yum list kubeadm --showduplicates # 别安装最新版本的,阿里云镜像可能没有该软件包 # 安装 kubelet kubeadm kubectl yum install -y kubelet-1.23.6-0 kubeadm-1.23.6-0 kubectl-1.23.6-0 --disableexcludes=kubernetes # 启动 kubelet,并且设置为开机启动 # 该处启动会失败,执行 kubeadm init 后该服务器会启动成功 systemctl enable --now kubelet # 检查 kubelet 是否启动成功 # kubeadm init 执行后 该服务还是启动失败,则需检查失败原因 systemctl status kubelet # 设置拉取kubeadm所需docker镜像源 kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers # kebeadm 初始化 # 首先需要先登录alibab的镜像仓库 # docker login registry.aliyuncs.com # --control-plane-endpoint 配置control-plane-endpoint,如果是多个则配置代理地址,例如k8s高可用集群的VIP地址。 # 192.168.1.188:6443 是 HA VIP 地址,该地址需要提前准备好 # 1.23.6的版本向上发布svc时端口netstat查不到 kubeadm init \ --pod-network-cidr=10.244.0.0/16 \ --service-cidr=10.96.0.0/12 \ --control-plane-endpoint=192.168.1.200:6443 \ --image-repository=registry.aliyuncs.com/google_containers \ --kubernetes-version v1.23.6 \ --upload-certs # 上面的指令安装成功后,执行下面的去污点指令 # 允许master部署pod kubectl taint nodes --all node-role.kubernetes.io/master:NoSchedule- # 根据这个提示安装 # 每次重新安装后必须执行下面的命令,老的权限文件不能在新的服务中执行 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config export KUBECONFIG=/etc/kubernetes/admin.conf # 安装网络 # 启动时需要设置 --pod-network-cidr=10.244.0.0/16 # 因为 kube-flannel.yml 文件中添加了 10.244.0.0/16 网段 # [flannel](https://github.com/flannel-io/flannel#deploying-flannel-manually) # ip link delete cni0 # 删除网卡 # ip link delete flannel.1 # 删除网卡 kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
kubeadm init 可选参数
可选参数
说明
–apiserver-advertise-address
指定API Server地址
–apiserver-bind-port
指定绑定的API Server端口,默认值为6443
–apiserver-cert-extra-sans
指定API Server的服务器证书
–cert-dir
指定证书的路径
–node-name
指定节点名称
–pod-network-cidr
指定pod网络IP地址段
–service-cidr
指定service的IP地址段
–service-dns-domain
指定Service的域名,默认为“cluster.local”
–token
指定token
–token-ttl
指定token有效时间,如果设置为“0”,则永不过期
–image-repository
指定镜像仓库地址,默认为”k8s.gcr.io”
–kubernetes-version
指定k8s版本
–dry-run
输出将要执行的操作,不做任何改变,预运行命令,不会真正的初始化服务
k8s服务重启
k8s服务依赖kubelet,该服务重启成功后,整个服务将会启动成功
1 systemcl restart kubelet
安装命令自动补全 1 2 3 4 5 6 7 8 9 10 # 安装 bash-completion yum install bash-completion # 在 bash 中设置当前 shell 的自动补全 source <(kubectl completion bash) source <(kubeadm completion bash) # 在你的 bash shell 中永久地添加自动补全 echo "source <(kubectl completion bash)" >> ~/.bashrc echo "source <(kubeadm completion bash)" >> ~/.bashrc
安装 dashboard 1 2 3 4 5 6 7 # https://github.com/kubernetes/dashboard#kubernetes-dashboard kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml # 访问 # dashboard 只能是内网或者是https访问 kubectl proxy --address=0.0.0.0 --port=8001 --accept-hosts='^*$' http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
添加worker节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 加入k8s集群,如果不知道token,执行下面的命令生成新的 kubeadm join 192.168.1.142:6443 --token ousz63.f5iny5ldc452ifey \ --discovery-token-ca-cert-hash sha256:7c51d82bcd16348d7a4b28a3bb4865694c3adafcba18d32326c8e427df215258 # token过期了, 生成一个24h后过期的token kubeadm token create --print-join-command # 生成一个永久的 kubeadm token create --ttl=0 --print-join-command # 查询所有的token kubeadm token list # 如果你没有 --discovery-token-ca-cert-hash 的值,执行下面的命令查询token-ca-cert-hash值。所有的token对应的证书值都是一样的。 openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' # 在其他节点上面操作k8s集群 # 将控制面板的 admin.conf 配置文件复制到本服务器 cd $HOME scp root@<control-plane-host>:/etc/kubernetes/admin.conf . mkdir -p $HOME/.kube cp -i $HOME/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config
添加control plane节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 获取token及token证书 kubeadm token create --print-join-command > kubeadm join 192.168.1.142:6443 --token ocusf1.kd5vvk6t1sj3hvf7 \ --discovery-token-ca-cert-hash sha256:e35c83e987090c9157816ad1741151b97ec78a3e89d2b39f24425993bb4e2634 # 获取control-plane证书 kubeadm init phase upload-certs --upload-certs > 2b820018d17d8cbd7680f5c6fc42e05995cce859e48b98a10326cd758750abf3 # 加入集群 第一个命令和第二个命令组合使用 kubeadm join 192.168.1.142:6443 --token ocusf1.kd5vvk6t1sj3hvf7 \ --discovery-token-ca-cert-hash sha256:e35c83e987090c9157816ad1741151b97ec78a3e89d2b39f24425993bb4e2634 \ --control-plane --certificate-key 2b820018d17d8cbd7680f5c6fc42e05995cce859e48b98a10326cd758750abf3 # 注意:第一次添加节点一般会出现下面的错误 The cluster has a stable controlPlaneEndpoint address. 集群没有稳定的controlPlaneEndpoint错误,解决方案在下面的安装问题记录中。
删除节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # control plane节点上执行下面的命令 # # 使用适当的凭证与控制平面节点通信,运行: kubectl drain <node name> --delete-emptydir-data --force --ignore-daemonsets # 删除节点: kubectl delete node <node name> --- # 在被删除的节点上执行下面的命令 # # 节点服务器上面重置 kubeadm 安装状态: kubeadm reset # 下面的命令重置所有的iptables设置 # 重置过程不会重置或清除 iptables 规则或 IPVS 表。如果你希望重置 iptables,则必须手动进行: iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X # 如果要重置 IPVS 表,则必须运行以下命令: ipvsadm -C
节点污点[taint]和pod容忍度[toleration]
节点污点有点类似节点上的标签或注解信息,它们都是用来描述对应节点的元数据信息;
pod容忍度表示pod要想运行在对应有污点的节点上,对应pod就要容忍对应节点上的污点;
污点的三个效用[effect]
NoSchedule 表示拒绝pod调度到对应节点上运行
PreferSchedule 表示尽量不把pod调度到此节点上运行
NoExecute 表示拒绝将pod调度到此节点上运行,比NoSchedule更加严格
pod污点容忍度通过下面的配置来设置 1 2 3 4 5 6 7 8 9 10 11 12 kind: pod spec: tolerations: - key: node-role.kubernetes.io/master # Equal 或者 Exists # Equal key和value都要相等 # Exists key相等就行,value不做考虑 operator: Equal value: # 没有值可以不填 effect: NoSchedule containers: - ...
1 2 3 4 5 6 7 8 9 10 11 # 查看污点 kubectl describe node etcd2 | grep Taint > Taints: node-role.kubernetes.io/master:NoSchedule # # 删除污点 # 在上面的node-role.kubernetes.io/master:NoSchedule最后加上- kubectl taint node etcd2 node-role.kubernetes.io/master:NoSchedule- # 添加污点 # --overwrite 覆盖原有的污点 kubectl taint node etcd2 node-role.kubernetes.io/master:NoSchedule [--overwrite]
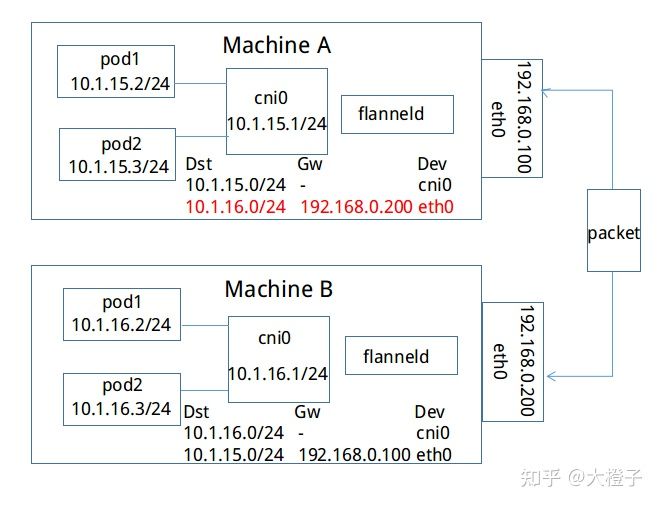
flannel 网络 Kubernetes 集群中的每个主机都有自己一个完整的子网,不同节点上的Pod无法进行通信。
Pod 通过安装在每个节点上的 flannel-deamonset 进行跨节点通信。
安装问题记录 1 2 3 # 查询指定服务启动问题 journalctl -xefu kubelet tail -f /var/log/message
failed to load Kubelet config file /var/lib/kubelet/config.yaml 1 2 # kubeadm init 没有执行 kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository=registry.aliyuncs.com/google_containers
hostname “mq” could not be reached 1 2 3 # 将 mq 加入到 /etc/hosts vi /etc/hosts 127.0.0.1 mq
container runtime is not running: output: time=”2022-05-05T11:17:59+08:00” level=fatal msg=”getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService” 1 2 3 4 # 出现这个可能是版本问题,降低个版本 # 下面的命令可以不执行 rm /etc/containerd/config.toml systemctl restart containerd
kubelet cgroup driver: "systemd" is different from docker cgroup driver: "cgroupfs" 配置驱动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 查看 docker 驱动 docker info | grep group # 将 docker cgroupfs 驱动修改为 systemd vi /etc/docker/daemon.json { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } systemctl daemon-reload systemctl restart docker
1 2 3 4 5 6 # 查看日志 tail -f /var/log/messages "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized" # 原因是没有初始化网络 kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
第一次加入control plane的时候会有以下报错:集群没有稳定的controlPlaneEndpoint 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@etcd2 ~]# kubeadm join 192.168.1.142:6443 --token ocusf1.kd5vvk6t1sj3hvf7 --discovery-token-ca-cert-hash sha256:e35c83e987090c9157816ad1741151b97ec78a3e89d2b39f24425993bb4e2634 --control-plane --certificate-key 2b820018d17d8cbd7680f5c6fc42e05995cce859e48b98a10326cd758750abf3 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' error execution phase preflight: One or more conditions for hosting a new control plane instance is not satisfied. unable to add a new control plane instance to a cluster that doesn't have a stable controlPlaneEndpoint address Please ensure that: * The cluster has a stable controlPlaneEndpoint address. * The certificates that must be shared among control plane instances are provided. To see the stack trace of this error execute with --v=5 or higher # 检查命名空间kube-system下面ConfigMap中的kubeadm-config配置中是否包含controlPlaneEndpoint kubectl -n kube-system get configmap kubeadm-config -o yaml kubectl -n kube-system get cm kubeadm-config -o yaml # 修改kubeadm-config配置,添加controlPlaneEndpoint kubectl -n kube-system edit cm kubeadm-config # controlPlaneEndpoint的大概的位置 kind: ClusterConfiguration kubernetesVersion: v1.18.0 controlPlaneEndpoint: 192.168.1.142:6443
“Error adding pod to network” err=”failed to delegate add: failed to set bridge addr: "cni0" already has an IP address different from 10.244.1.1/24” pod=”5g/user-pod-59549ff4c9-9cg67”
节点加入了k8s集群多次,重新加入后没有重启docker,导致原有的网络和现在冲突
1 2 3 4 5 6 7 8 9 10 11 12 13 # 检查当前节点的cni的ip地址 ifconfig > cni0:inet 10.244.2.1 和 10.244.1.1/24 不一致 # 执行下面的命令 ifconfig cni0 down ifconfig flannel.1 down ip link delete cni0 ip link delete flannel.1 systemctl restart docker # 上述如果不行,下线docker网卡重新启动 ifconfig docker0 down
connect: no route to host